在上一篇我们只是分析了fmp4的结构,也就是box的结构组成,但是还是需要进行remuxer才可以将flv转成fmp4。
Metadata
在flv那边我们有提到parseAACAudioSpecificConfig、parseAVCDecoderConfigurationRecord,其实在那里会通过this._onTrackMetadata这个方法将对应的音视频的metadata传给mp4-remuxer去处理。而script tag的metadata没有交给fmp4处理,相信大家也明白,这个数据主要是一些媒体信息。
Audio Metadata
让我们再回到flv-demuxer,在解析Audio时会优先解析Audio Metadata,也就是音频的Audio Object Type,channel,codec等信息。解析完毕之后会将这些信息都传递给mp4-remuxer去处理,生成metabox。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36// 'audio/mp4, codecs="codec"'
metabox = MP4.generateInitSegment(metadata);
// 所以第一次初始化 metadata 的数值填给 fmp4 中的对应数值,其他的都可以使用默认值
-> ftyp 固定的,这部分不多说,见上一篇FMP4结构那篇文章
-> moov
-> mvhd: timescale, duration
-> trak
-> tkhd: trackId, duration, width, height
-> mdia
-> mdhd: timescale, duration
-> hdlr: hdlr_audio
-> minf
-> xmhd: smhd
-> dinf
-> dref
-> stbl
-> stsd
/-> mp3: channelCount, sampleRate
/-> mp4a(aac): channelCount, sampleRate
-> esds: config, configSize
-> stts
-> stsc
-> stsz
-> stco
-> mvex
-> trex: trackId
// 到这里就完成了 Audio 的 InitSegment。
this._onInitSegment(type, {
type: type,
data: metabox.buffer,
codec: codec,
container: `${type}/${container}`,
mediaDuration: metadata.duration // in timescale 1000 (milliseconds)
});
Video Metadata
同理,Video在解析数据之前,第一个会是AVC Decoder Configuration Record,即会把chromaFormat、duration、frameRate、presentHeight、presentWidth等数据一样传递给mp4-remuxer,跳过 ftyp 不说,会跟Audio一样产生一个 moov 的box。这里只挑跟Audio不同的数据。1
2
3
4
5
6
7
8
9
10// 'video'
metabox = MP4.generateInitSegment(metadata);
// Video metadata
hdlr: hdlr_video
xmhd: vmhd
stsd
-> avc1: avcc, width, height
// 可以看到,其实只要有meta传参的地方,数据都是不一样的(部分没写出来)
Data
读取完 metadata 之后,之后读取到 audio 的,就是AAC raw frame data数据了,然后将数据保存到 audio track 中的 sample 数组;当然 video 也是一样,之后的数据就是nalus了,然后同时也将数据保存到 video track 中的 sample 数组。待抓取到的媒体流数据解析完成之后,将解析完的数据帧发送给remuxer。1
2
3
4this._onDataAvailable(this._audioTrack, this._videoTrack);
// ===>>> mp4-remuxer::remux
this._remuxVideo(videoTrack);
this._remuxAudio(audioTrack);
在这里注意一下,在进行remuxVideo跟remuxAudio之前,会先计算一个base dts,这个是什么呢?之后再说。
Video Data
我们拿 video data 来分析,实际上分析了 video data,那么 audio 的部分也是大同小异的了。这里先将 nal 的数据转为 mdat box,这部分参考FMP4结构的BOX部分。这里先写入的是 nal 的头部信息。也就是size、type这些。并不包括真正的数据。1
2
3
4
5
6
7
8let offset = 8;
let mdatBytes = 8 + videoTrack.length;
let mdatbox = new Uint8Array(mdatBytes);
mdatbox[0] = (mdatBytes >>> 24) & 0xFF;
mdatbox[1] = (mdatBytes >>> 16) & 0xFF;
mdatbox[2] = (mdatBytes >>> 8) & 0xFF;
mdatbox[3] = (mdatBytes) & 0xFF;
mdatbox.set(MP4.types.mdat, 4);
为了修正后续的 samples 能与上一次的 samples 形成连续性(MSE要求连续的segments之间是不能存在时间戳间隙),所以取这次 samples 中第一个 sample 的时间戳,追加到上一次 samples 末尾的位置,根据差值(dtsCorrection),后面所有 sample 时间戳做相应平移。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// calculate dtsCorrection
if (this._videoNextDts) {
dtsCorrection = firstSampleOriginalDts - this._videoNextDts;
} else { // this._videoNextDts == undefined
if (this._videoSegmentInfoList.isEmpty()) {
dtsCorrection = 0;
} else {
// 假如 _videoNextDts 为 undefined,则根据时间戳从_videoSegmentInfoList 中找到最后一个 sample 的信息
let lastSample = this._videoSegmentInfoList.getLastSampleBefore(firstSampleOriginalDts);
if (lastSample != null) {
let distance = (firstSampleOriginalDts - (lastSample.originalDts + lastSample.duration));
if (distance <= 3) {
distance = 0;
}
let expectedDts = lastSample.dts + lastSample.duration + distance;
dtsCorrection = firstSampleOriginalDts - expectedDts;
} else { // lastSample == null, cannot found
dtsCorrection = 0;
}
}
}
下面的一步其实目的就很明了了,就是根据上面产生的差值,来给每一个 sample 时间戳做相对应的平移。并且输出 mp4Samples 。
还记得上面的mdatbox吗?我们之前只对它做头部信息处理,那么接下来的一步就是对它填充我们处理过后的数据。1
2
3
4
5
6
7
8
9
10// Write samples into mdatbox
for (let i = 0; i < mp4Samples.length; i++) {
let units = mp4Samples[i].units;
while (units.length) {
let unit = units.shift();
let data = unit.data;
mdatbox.set(data, offset);
offset += data.byteLength;
}
}
生成 moof box。1
2
3
4
5
6
7-> moof
-> mfhd: sequence number
-> traf
-> tfhd: trackId
-> tfdt: baseMediaDecodeTime,也就是一次 packets 的firstDts
-> sdtp: isLeading,dependsOn,isDependedOn,hasRedundancy
-> trun: sampleCount,offset,sample(duration,size,flags,cts)
生成完之后需要对这一次的 sample list 清空。1
2track.samples = [];
track.length = 0;
最后将数据box合并,并将此次的数据派发出去。
Audio Data
Audio这里分为AAC跟MP3这两类音频解码格式。我们就针对AAC这一类来,MP3也是大同小异的,因为只有Firefox支持'audio/mp4,codecs="mp3"'。calculate dtsCorrection 这部分就不多讲了。跟上面 Video Data 道理一样。但是这里作者做了一个兼容处理,就是为了解决 Edge seek 后卡住的 bug。作者这一块是这样解释的: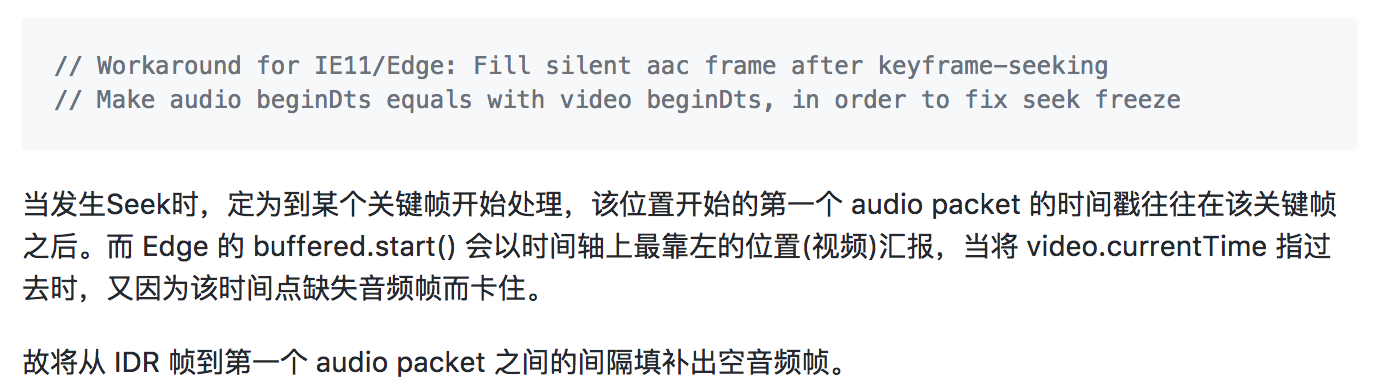
这里注意一下:videoSegment.beginDts < firstSampleDts,假如该空音频是在第一帧,那么就没必要补帧了(AAC.getSilentFrame),补帧的道理也是为了使其数据连续性。Correct dts for each sample这一步跟Video的处理差不多,只是多了一个large timestamp gap的处理,这个会产生音视频不同步。剩余的后面不讲。因为看注释以及跟Video data差不多。
音视频同步原理
最后讲一下音视频同步的原理。每一帧视频或音频都有一个duration,认识这一点很重要。然后采样率(sample rate)指的是每秒钟对音频信号的采样次数,采样频率越高声音还原度越高,声音更加自然。单位是赫兹 Hz。这里我们拿44.1kHz来讲,实际还有其他的,具体可以看FLV解析-AudioTag(1)。
视频帧播放时间:
- H.264:
duration = 1000 / fps,我们常见的 fps 有25,当然也有见过30的。那么 duration 就为40ms,也就是40ms一个视频帧。
音频帧播放时间:
- AAC:
duration = 1024 / sample_rate,AAC音频一帧有1024个采样样本,我们假如 sample rate 为 44.1kHz,那么 duration 应该为 23.22ms左右。 - MP3:
duration = 1152 / sample_rate,MP3音频一帧跟AAC不同,只有1152个采样样本,同样假设 sample rate 为 44.1kHz,那么 duration 为 26.12ms。
那么理论下的音视频同步如下:1
2
3
4
5
6
7--------------------------------------------------------------
时间轴:| 0 | 23.22 | 40 | 46.44 | 69.66 | 80 | ... | 116.1 |
--------------------------------------------------------------
音 频:| 0 | 23.22 | | 46.44 | 69.66 | | ... | 116.1 |
--------------------------------------------------------------
视 频:| 0 | | 40 | | 80 | ... | |
--------------------------------------------------------------
可以看得出,音视频的排列是按照起始时间戳从小到大来排序的,当然这部分可以允许些许波动,但也要注意一旦出现过大就会发现音视频不同步。例如: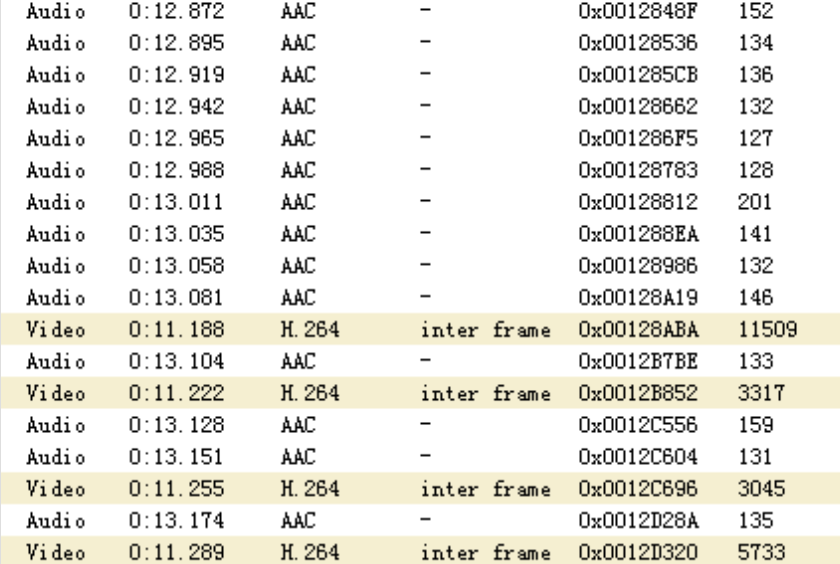
当然这是理论上,还需要考虑到其他的影响因素,例如硬件,网速之类的情况。

